# [A Visual Guide to Mixture of Experts](https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts) (Extends Chapter 3)
Chapter 3 gives a solid foundation for traditional transformer decoders and how they work. We also cover more advanced topics like efficient attention and advancements in positional embeddings.
One topic that we did not discuss in detail that has been gaining traction is called Mixture of Experts. It is a technique that enhances these transformer decoders by incorporating multiple specialized sub-networks or "experts."
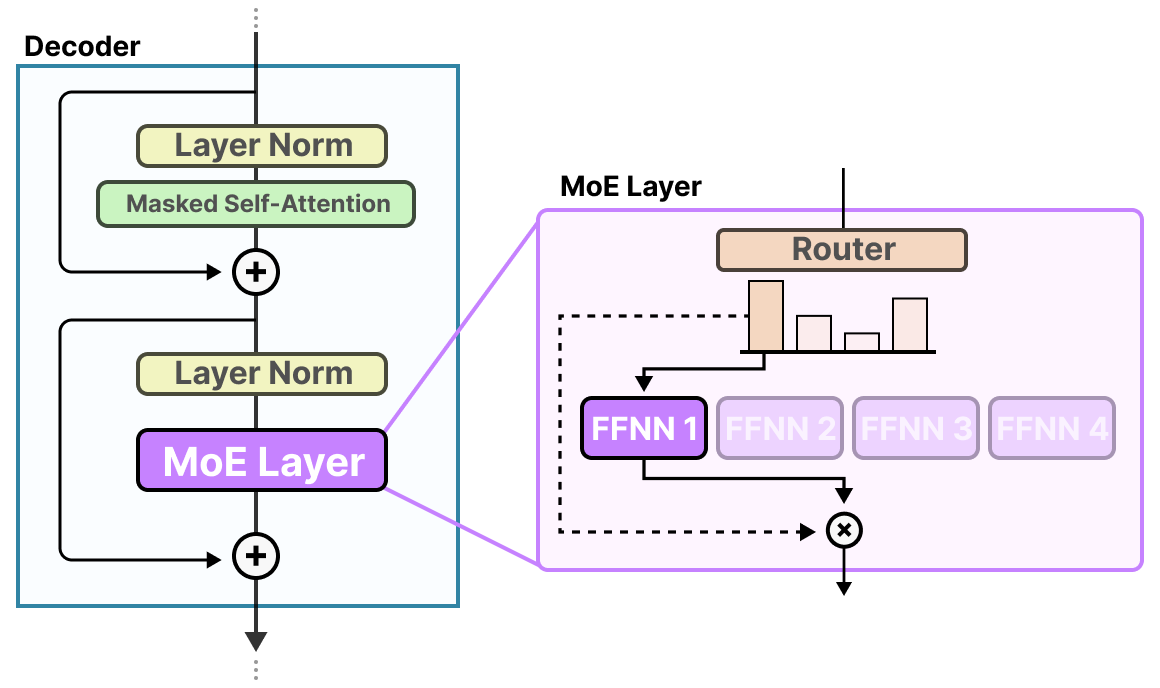 [A Visual Guide to Mixture of Experts (MoE)](https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts) illustrates how MoE models dynamically route different inputs to the most appropriate experts, allowing for more efficient processing of diverse language tasks.
As another bonus, the blog continues into the field of vision language models:
[A Visual Guide to Mixture of Experts (MoE)](https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts) illustrates how MoE models dynamically route different inputs to the most appropriate experts, allowing for more efficient processing of diverse language tasks.
As another bonus, the blog continues into the field of vision language models:
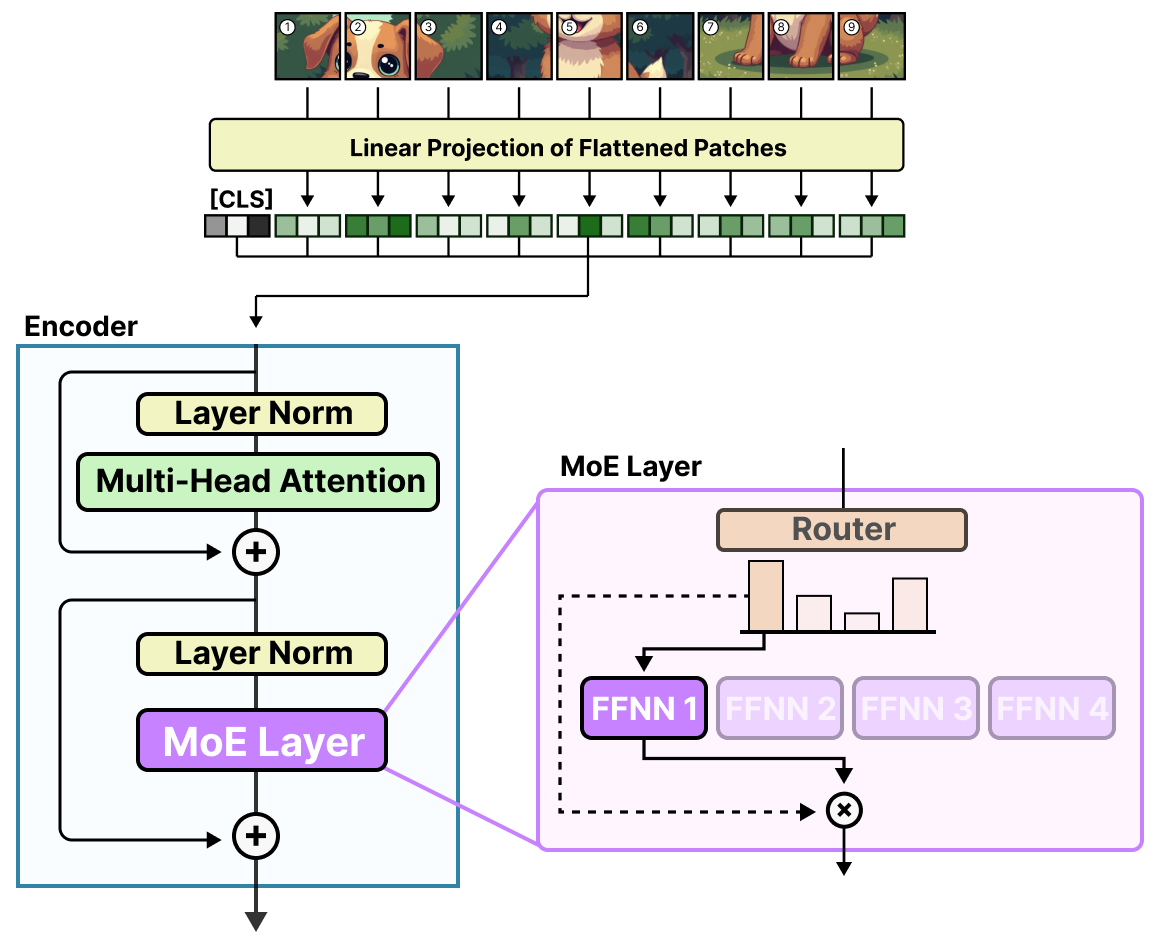 By connecting this advanced concept to the decoder fundamentals covered in Chapter 3, readers can quickly dive into the seemingly complex but in practice straightforward method of Mixture of Experts.
By connecting this advanced concept to the decoder fundamentals covered in Chapter 3, readers can quickly dive into the seemingly complex but in practice straightforward method of Mixture of Experts.