2.9 KiB
# The Illustrated DeepSeek-R1 (Extends Chapters 12)
In Chapter 12, we go through common techniques for creating and fine-tuning a model, namely language modeling, supervised fine-tuning and preference tuning. This chapter focuses on non-reasoning models and shows how you can fine-tune a model yourself.
The impact of DeepSeek-R1 has been phenomenol as an open-weights LLM rivaling OpenAI's o1 model. DeepSeek-R1 is a reasoning LLM that was released unexpectly.
The Illustrated DeepSeek-R1 explores the model and its training process. It goes through the various steps they use to create a model with such exception capabilities.
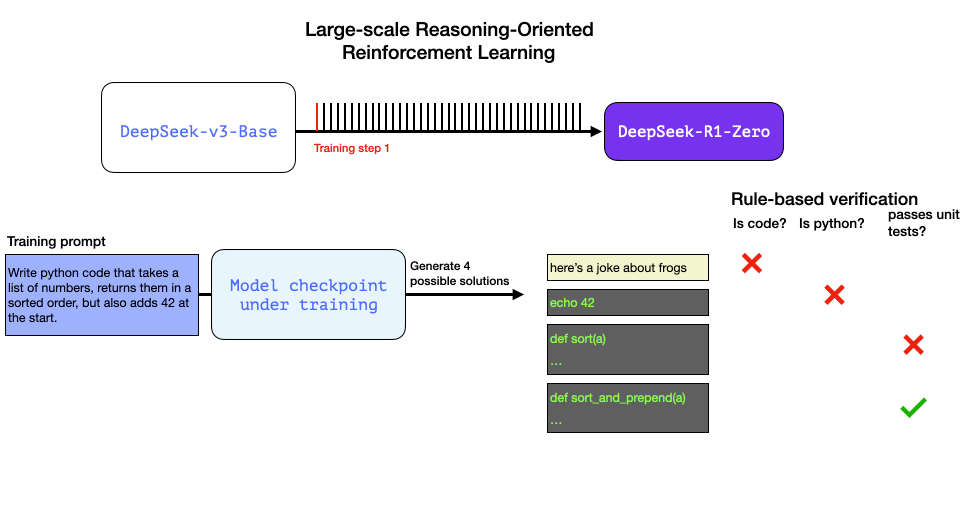
Interestingly, the model uses rule-based verifiers to make sure that it's reasoning process follows a certain standard, such as making sure that the code can actually compile:
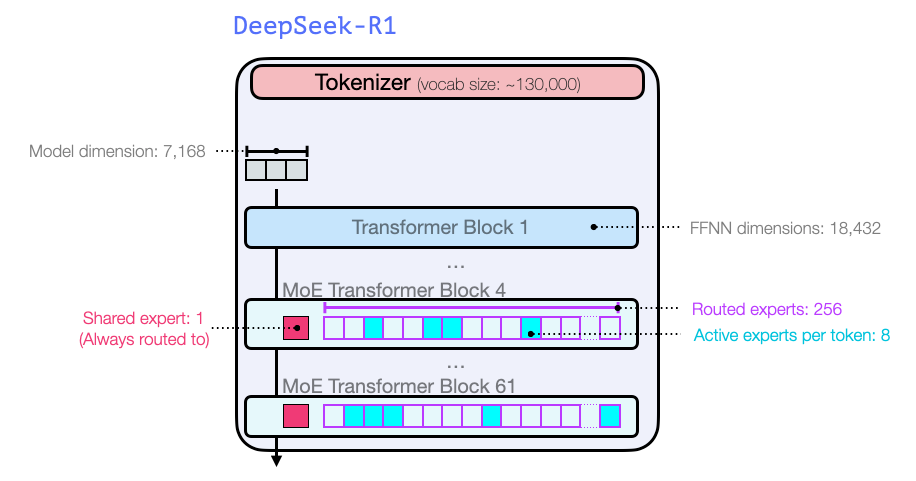
The architecture is that of a Mixture-of-Experts and with 256 experts (8 activated at a time), quite large: